![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
Mythos e i modelli di frontiera cambiano la sicurezza
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Zscaler ha testato Mythos di Anthropic e GPT 5.5 Cyber di OpenAI su scenari reali di attacco e difesa. I risultati ridefiniscono cosa significa trovare vulnerabilità e costruire exploit.




Costruire un exploit funzionante a partire da vulnerabilità già note oggi costa qualche migliaio di dollari in token e un giorno di lavoro. Sei mesi fa avrebbe richiesto un team di specialisti e settimane di lavoro. La differenza è nei nuovi modelli di frontiera; per capire esattamente cosa è cambiato (e come sfruttarlo a scopo difensivo) Zscaler ThreatLabz ne ha testati due su scenari reali di attacco e di difesa. Le conclusioni sono incluse nel post When the Scanner Starts Thinking: Learnings from Mythos & GPT 5.5 Cyber in Security Testing, in cui si spiega perché la sfida dei modelli di frontiera sarà la capacità di usarli in difesa prima che gli attaccanti li usino in attacco.
I modelli di frontiera scelti per il test sono stati Mythos di Anthropic e GPT 5.5 Cyber di OpenAI. Prima di iniziare è necessario fissare un punto: i modelli precedenti erano già utili per trovare vulnerabilità isolate; quello che Mythos e GPT 5.5 Cyber fanno di diverso è il ragionamento multi-step, che permette di passare da una semplice lista di problemi, a una catena di attacco che collega errori di configurazione, stati di privilegio e vulnerabilità. Il salto qualitativo è notevole, soprattutto se si considera che la capacità di concatenare vulnerabilità per costruire un percorso di attacco complesso è storicamente una delle competenze più rare e costose nell’ambito del penetration testing. Infatti, mettere insieme due vulnerabilità diverse per trovare una via di compromissione richiede tempo e competenza specialistica. Farlo con tre o quattro vulnerabilità aumenta la difficoltà in modo esponenziale. Una automazione di questa capacità, anche solo a livello di prototipo funzionante, rimuove di fatto una barriera che fino a poco tempo fa proteggeva indirettamente molte organizzazioni.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
Il framework di test
La domanda a cui hanno cercato risposta gli esperti di Zscaler è come si usano questi modelli in modo efficace, e che cosa producono quando li metti al lavoro su target reali? Per rispondere hanno costruito un framework di test organizzato intorno a tre scenari distinti, ciascuno pensato per simulare una prospettiva diversa sullo stesso target.
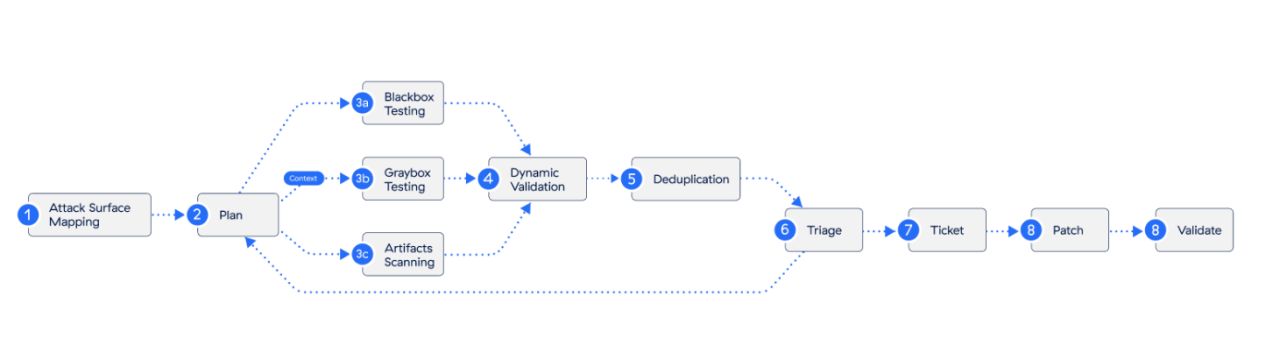 I tre principali scenari di test usati per valutare le capacità dei modelli di IA di frontiera
I tre principali scenari di test usati per valutare le capacità dei modelli di IA di frontiera
Il primo, definito black box, mette il modello nella posizione di un attaccante esterno senza accesso a informazioni interne: nessuna conoscenza del sistema, solo la visibilità sulla superficie esposta. Le vulnerabilità confermate in questo scenario vengono considerate immediatamente rilevanti perché replicano esattamente le condizioni in cui opera un threat actor reale.
Il secondo scenario lavora su artefatti e repository di codice: il modello ispeziona sorgenti, binari compilati e file statici alla ricerca di falle, prima che possano essere sfruttate. Produce meno risultati confermati rispetto agli altri approcci, ma si è rivelato particolarmente efficace nel decomporre sistemi complessi e generare output di qualità per la validazione dinamica successiva.
Il terzo scenario, gray box e white box, è quello che ha prodotto i risultati più interessanti. Qui il modello lavora con contesto parziale o completo: threat model, specifiche architetturali, risultati di scansioni precedenti. La qualità dell'output dipende direttamente dalla qualità del contesto fornito, ma quando il contesto è buono, il modello è in grado di identificare percorsi di compromissione con una precisione che i test senza contesto non avvicinano. Tutti e tre gli scenari condividono la stessa pipeline operativa: mappatura della superficie di attacco, pianificazione del test, testing attivo, validazione dinamica, deduplicazione, triage, ticketing, patching e validazione finale.
I risultati
Il dato aggregato indica che i modelli di frontiera hanno individuato il doppio dei risultati a severity alta rispetto agli strumenti legacy e ai penetration test tradizionali, con una velocità doppia. I risultati confermati presentavano inoltre percorsi di riproduzione chiari e indicazioni di remediation calibrate sul comportamento reale degli attaccanti. Il rapporto segnale/rumore (che storicamente è uno dei problemi più costosi nella gestione delle vulnerabilità) è migliorato in modo significativo rispetto agli approcci precedenti.
Tra le capacità valutate, Zscaler identifica l'attack chaining e l'analisi iterativa come le più rilevanti. L'attack chaining è la capacità di connettere vulnerabilità separate in percorsi di compromissione multi-stadio. L'analisi iterativa è la capacità di ragionare dinamicamente su un problema. Insieme, questi due elementi trasformano lo strumento da scanner evoluto a sistema in grado di simulare il processo cognitivo di un attaccante esperto.
Importante è sottolineare di nuovo che si partiva da vulnerabilità note, ossia da CVE già pubbliche, presenti nei database di sicurezza e teoricamente già gestite. Con questo bagaglio informativo è stato possibile costruire exploit kit funzionanti in tempi e a costi che fino a qualche mese fa erano semplicemente fuori portata per la grande maggioranza degli attaccanti. Il costo in token per costruire un exploit operativo, in scenari documentati, si è attestato nell'ordine delle migliaia di dollari: una cifra accessibile agli attaccanti motivati, inclusi quelli senza budget significativi. Qualcuno potrebbe mettere l’accento sul vantaggio di operare con falle già note, ma il punto è un altro, ossia che vulnerabilità note e teoricamente gestite diventano sfruttabili da chi prima non aveva le competenze per farlo.
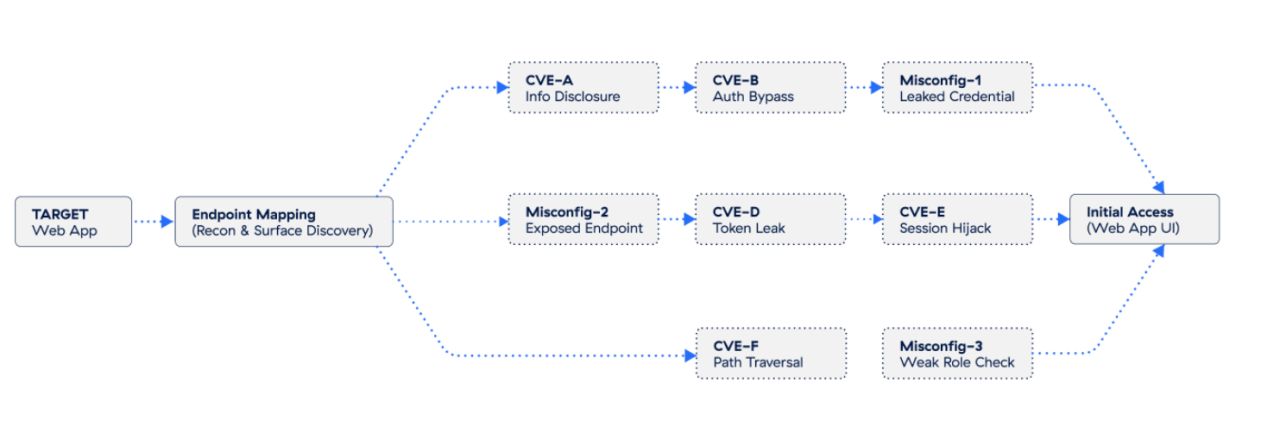 Tre percorsi indipendenti, un unico risultato convergente
Tre percorsi indipendenti, un unico risultato convergente
C’è poi un’altra questione legata alle vulnerabilità note date in dote ai modelli, che è controintuitiva ma importante. Fornire al modello di vulnerabilità note lo porta a concentrarsi su quel tipo di falla e a non cercare falle differenti e inedite, perché il modello si "fissa" su quello che conosce e perde la capacità esplorativa. La morale è che il contesto aiuta, ma dev’essere dosato per trovare il giusto compromesso. E dev’esserci per forza perché in sua assenza, o insufficienza, i modelli tendono a sovrastimare la severity di quello che scoprono perché non riescono a valutare correttamente le dipendenze tra componenti. La calibrazione del contesto (quanto fornirne, di che tipo, in quale forma) emerge come una competenza in sé, non meno importante della qualità del modello.
Facciamo un passo avanti e supponiamo il caso in cui chi usa il modello ha trovato tutte le vulnerabilità presenti in un ambiente. Chi difende non è nella posizione di risolverle tutte immediatamente: ogni patch richiede la valutazione degli impatti, le approvazioni del caso, la pianificazione della finestra di patch (soprattutto se in ambiente OT o IoT), test di regressione, coordinamento tra team. Gli attaccanti non hanno questo problema. Questo è il motivo per il quale, se i modelli venissero utilizzati su larga scala senza che le organizzazioni avessero già avviato processi di remediation accelerata, il vantaggio immediato andrebbe a chi attacca. Si apre quindi uno scenario in cui l’esigenza non è solo trovare le vulnerabilità prima dei threat actor, ma essere in grado di chiuderle più velocemente di quanto un avversario riesca a sfruttarle.
Che cosa fare, quindi? Le raccomandazioni di Zscaler partono da un principio che non è nuovo ma che con i modelli di frontiera diventa urgente in modo diverso: ridurre la superficie esposta prima di preoccuparsi di come analizzarla. Un'applicazione che non è raggiungibile dall'esterno non può essere sfruttata da un modello che opera dall'esterno. Le architetture Zero Trust (in particolare la segmentazione utente-applicazione) riducono la portata dannosa (tecnicamente il blast radius) di qualsiasi attacco condotto con l’AI che riesce a trovare un punto di ingresso.
Il secondo livello di analisi riguarda la visibilità. I modelli di frontiera sono più efficaci quanto più il difensore conosce il proprio ambiente. Asset management completo, exposure management, attack surface management esterno sono la condizione abilitante per usare gli stessi strumenti offensivi in chiave difensiva. Chi non sa cosa ha esposto non può usare un modello per trovare i propri punti deboli prima che lo faccia qualcun altro.
Il terzo punto riguarda i modelli AI usati in produzione. Le imprese sono ormai obbligate a trattare i propri sistemi AI come superficie di attacco reale. L'ultimo punto, e forse il più significativo per chi deve prendere decisioni operative, riguarda la composizione dei team. Le persone che oggi si occupano di remediation manuale potrebbero essere più utili a guidare i modelli nel contesto specifico dell'organizzazione, mettendo a frutto la propria conoscenza dell'ambiente, la struttura operativa, i limiti e i pregi tecnici. Questa conoscenza contestuale non è replicabile da un modello esterno ed è l’arma segreta dei frontier model usati a difesa delle infrastrutture.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate











Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
Violence-as-a-service: quando il ransomware minaccia violenza fisica
10-07-2026
L’AI cambia le tempistiche di distribuzione delle patch di Windows
10-07-2026
Turismo sotto attacco: phishing triplicato negli ultimi tre anni
10-07-2026
AI agentica, su AWS arrivano controlli di sicurezza per gli agenti
09-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
