![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
Claude Code, il leak del sorgente apre una nuova kill chain AI
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Il leak del codice di Claude Code espone i punti deboli di un agent AI scritto in parte da un LLM: attacchi alla supply chain, data poisoning e sfiducia verso uno strumento che può agevolare operazioni mirate.




Dopo il data leak che ha rivelato l’esistenza del modello avanzato Claude Mythos, un altro errore umano ha portato all’esposizione pubblica del codice sorgente completo di Claude Code. L’incidente rientra nella lunga tradizione degli errori di packaging che hanno esposto asset sensibili (in questo caso una banale svista nella pubblicazione su NPM). Il guaio è che dentro a quel pacchetto c’erano 513.000 linee di TypeScript, 1.906 file, inclusi componenti sensibili come hook di esecuzione, componenti di orchestrazione agentica, gestione di permessi e feature non ancora rilasciate.
In particolare, la presenza nel leak dei file di mappatura ha consentito la ricostruzione del codice sorgente, esponendo l’intera logica dell’agent. Significa che dal momento del leak la superficie d’attacco si è ampliata in modo significativo, con i threat actor che hanno potuto analizzare il codice, comprenderne il funzionamento interno e, soprattutto, individuarne numerosi punti deboli. Zscaler ha già documentato la comparsa di repository fake su GitHub che sfruttavano il leak come esca per distribuire malware come Vidar e GhostSocks, che è una dinamica classica legata ai leak di software ad alta visibilità.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
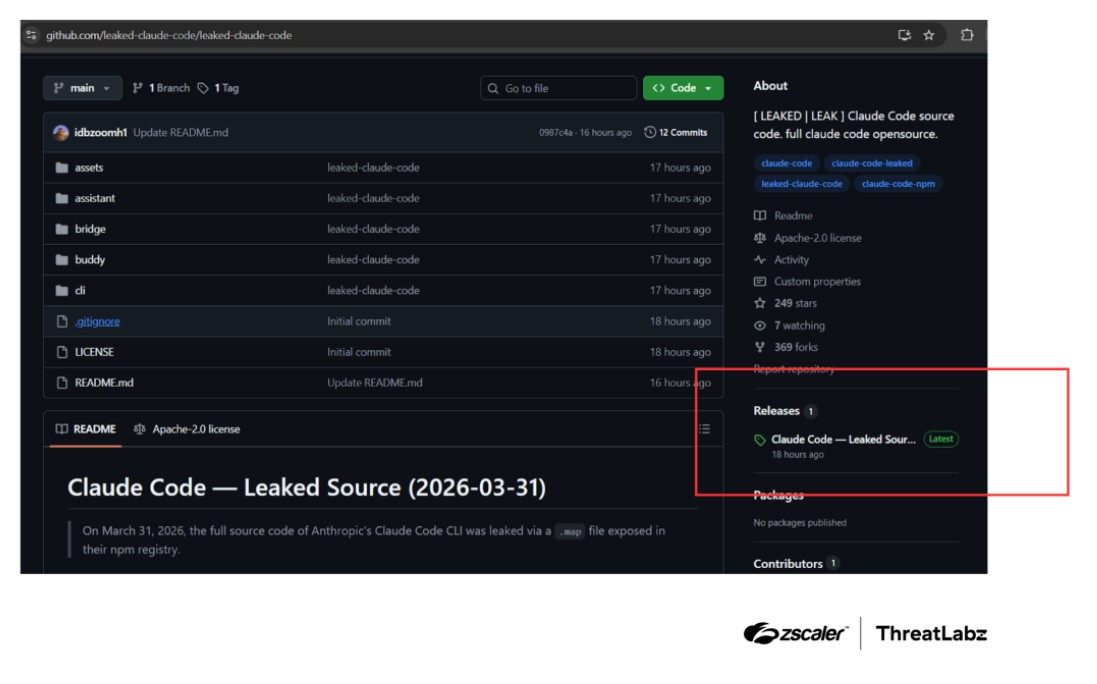 Fonte: Zscaler
Fonte: Zscaler
Più di un aiuto agli attaccanti
Il problema vero è la fase successiva della kill chain, ossia la possibilità di manipolare o ricompilare il codice esposto, rilevarne gli eventuali punti deboli e usarli nella creazione anche di attacchi alle supply chain. L’analisi del sorgente e dei commenti interni suggerisce che una parte del codice sia stata generata automaticamente dal modello, come del resto Anthropic aveva già indicato descrivendo Claude Code come un ibrido tra componenti tradizionali e blocchi generati da LLM. Fino a oggi nessuno aveva potuto vederci chiaro e trovare una risposta alla domanda: quanto è grave che ci sia codice generato da un LLM all’interno di un prodotto che governa l’esecuzione di altri LLM?
Il problema di fondo è che Claude Code non è un semplice strumento di sviluppo, è un agent AI progettato per operare all’interno di ambienti sensibili, con la capacità di interagire con file, processi e sistemi. E nel momento in cui il codice di base è altamente prevedibile si apre un problema di sicurezza. Gli esperti di Zscaler hanno spulciato il codice del leak e hanno trovato quello che temevano: alcune parti del codice di Claude Code presentano pattern tipici della generazione automatica, ossia strutture ripetitive, commenti sintetici, scelte stilistiche uniformi, che incidono sulla prevedibilità del software e di conseguenza facilitano la creazione di exploit mirati.
 Schema del Gatekeeper Pattern, l’architettura che separa funzioni privilegiate e modelli esposti a dati non affidabili. Fonte: NCC
Schema del Gatekeeper Pattern, l’architettura che separa funzioni privilegiate e modelli esposti a dati non affidabili. Fonte: NCC
La questione non è nuova. Wiz Research in un report del 2024 dedicato alla sicurezza degli agenti AI aveva avvisato che la prevedibilità dei modelli linguistici sarebbe potuta diventare un vantaggio per gli attaccanti, soprattutto quando il codice che così generato viene utilizzato in componenti critici. Trail of Bits nel 2023 spiegava che gli LLM tendono a produrre codice apparentemente corretto, ma spesso privo di difese efficaci nella gestione di condizioni limite o input malevoli. Nel caso di Claude Code è anche peggio, perché convive una combinazione di parti scritte manualmente e di parti generate automaticamente che crea un terreno fertile per analisi differenziali e per nascondere alterazioni minime all’interno di strutture che appaiono del tutto legittime, pericolosamente efficaci quando si dispone di versioni multiple o parziali dello stesso software.
La kill chain si affina
Lasciamo da parte la filosofia e proseguiamo con la kill chain: la potenziale compromissione del codice apre alla possibilità di introdurre backdoor o vulnerabilità, ma non solo. È importante rilevare che il leak consente agli attaccanti di comprendere come l’agent gestisce i permessi, quali controlli applica e quali valutazioni svolge sul comportamento dell’utente. Tale comprensione apre scenari molto più ampi, perché consente di modellare l’attacco attorno al comportamento previsto del software. Parliamo di un vantaggio strategico utile alla costruzione di operazioni low‑and‑slow calibrate per muoversi entro i confini che l’agent considera legittimi. In questo modo l’attività malevola non genera segnali anomali, si confonde con il flusso operativo ordinario, replicando la dinamica che ha reso efficace l’attacco SolarWinds: un componente compromesso che agisce in un contesto di fiducia elevata e che, proprio per questo, può operare senza attirare l’attenzione.
La conoscenza dei controlli interni dell’agent consente inoltre di intervenire sulle pipeline di sviluppo. Come sottolineato sopra, Claude Code non è un editor passivo, quindi un attaccante che ne conosce le logiche può alterare file di build, modificare dipendenze, introdurre configurazioni pericolose o manipolare script di automazione, senza intervenire direttamente sul codice dell’applicazione. È un tipo di compromissione pericolosa proprio perché si propaga in modo silenzioso, ed è il motivo per il quale Google, nel Secure AI Framework, ha evidenziato che il passaggio da sistemi AI tradizionali ad agenti autonomi amplifica drasticamente il perimetro di una compromissione. L’azienda di Mountain View incentiva l’applicazione di controlli più stringenti su permessi, osservabilità e accesso agli strumenti integrati.
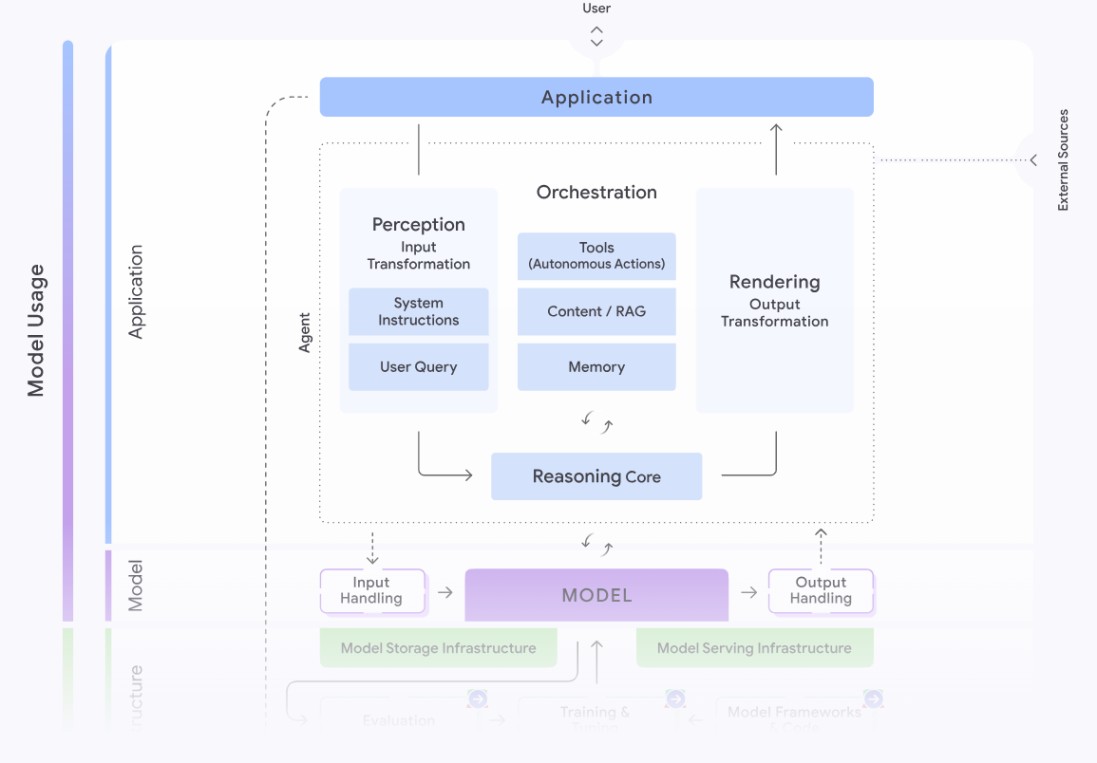 I componenti operativi di un agente AI secondo il Secure AI Framework (SAIF): un’architettura complessa che, se compromessa, può amplificare i rischi lungo l’intera supply chain
I componenti operativi di un agente AI secondo il Secure AI Framework (SAIF): un’architettura complessa che, se compromessa, può amplificare i rischi lungo l’intera supply chain
Seguendo il fil rouge della manipolazione del codice, qualora un attaccante conoscesse le condizioni che portano l'agent a ignorare un controllo, a sovrascrivere un file o ad accettare una dipendenza non verificata, potrebbe facilmente costruire input che lo spingono a compiere azioni borderline senza che l'utente se ne accorga. È un'eventualità analizzata da NCC Group, che ha evidenziato come il rischio di excessive agency (la condizione in cui un modello ha accesso a funzioni privilegiate oltre il necessario), quando si combina con la manipolazione degli input tra zone di trust differenti, crei percorsi di compromissione poco visibili che sfuggono ai controlli tradizionali.
Nel suo report, Zscaler ha individuato un rischio immeditato: sono già in circolazione repository che replicano il nome e la struttura del progetto originale, ma che contengono payload nascosti. È una tecnica che sfrutta la fiducia degli sviluppatori e la velocità con cui gli strumenti AI vengono adottati. CrowdStrike, nel suo Global Threat Report, ha più volte sottolineato che gli attacchi alla supply chain sono diventati uno dei vettori preferiti dai threat actor più sofisticati perché permettono di colpire un numero elevato di vittime attraverso un singolo punto di compromissione, quello che sta accadendo ne è la concretizzazione.
In questa visione, l’ultima fase della kill chain avviene quando uno sviluppatore o un agente AI scarica o integra un fork compromesso. La presenza di codice generato automaticamente può rendere più difficile individuare anomalie, perché il confine tra ciò che è “strano” e ciò che è semplicemente frutto della generazione automatica è molto sfumato. È un problema che diversi ricercatori hanno evidenziato negli ultimi mesi. Bruce Schneier, nell'agosto 2025, ha pubblicato un post intitolato LLM Coding Integrity Breach in cui i commentatori hanno discusso esattamente del problema del codice generato da LLM con bug difficili da individuare.
Oltre agli scenari di exploit tradizionali, il leak del sorgente di Claude Code si inserisce in un quadro più ampio in cui poisoning dei dati e degli agent è diventato uno dei vettori di attacco più discussi. Diversi studi recenti hanno mostrato che bastano percentuali minime di dati avvelenati per introdurre backdoor stabili nel comportamento dei modelli, anche in LLM di grandi dimensioni.
Quando questi modelli vengono usati come agent dotati di memoria persistente, il rischio aumenta: attacchi come il memory poisoning dimostrano che è possibile iniettare istruzioni malevole nella memoria dell’agent tramite semplici interazioni testuali, influenzando in modo duraturo le decisioni successive. In architetture multi‑agent o orchestrate, dove più agent condividono contesto e tool, un singolo agent compromesso può propagare contenuti contaminati agli altri, creando percorsi di compromissione che sfuggono alle difese progettate per applicazioni monolitiche. In questo scenario, un sorgente altamente prevedibile e in parte generato automaticamente, come quello di Claude Code, rischia di diventare un acceleratore per chi vuole studiare come sfruttare memory, contesto condiviso e privilegi eccessivi al fine di costruire attacchi di lungo periodo difficili da rilevare.
 LLM poisoning. Fonte: ai.plainenglish.io
LLM poisoning. Fonte: ai.plainenglish.io
È in questo passaggio che il parallelo con SolarWinds diventa inevitabile. Non per la natura dell’attacco, ma per la logica che lo sostiene: quando viene manipolato un componente software che funge da snodo nella supply chain, la compromissione non resta confinata al singolo pacchetto. SolarWinds ha dimostrato che un aggiornamento apparentemente legittimo può trasformarsi in un vettore capace di propagarsi in modo silenzioso verso ogni ambiente che lo integra. Nel caso di Claude Code, la disponibilità del sorgente rende più semplice costruire versioni alterate che imitano perfettamente quelle originali, con il rischio di replicare dinamiche già viste in passato.
Serve una mediazione culturale
In linea teorica, un modello dovrebbe essere dotato di controlli di security atti a impedire che tutto questo - o anche solo una delle possibilità citate - si possa attuare. In realtà, il leak rivela che esistono sì controlli interni, ma che alcuni di essi sono più orientati alla funzionalità che alla sicurezza. È un approccio che ricorda quanto osservato in vari audit sugli agenti AI: la tendenza a privilegiare la fluidità dell’interazione rispetto alla rigidità dei confini di sicurezza, che per ovvii motivi non può essere promossa da un’analisi di security.
L’incidente di Claude Code è un’occasione per riflettere sul modo in cui i vendor affrontano il tema della sicurezza degli agent AI. Anthropic ha sempre sostenuto un approccio orientato alla security, con un forte accento sulla mitigazione dei rischi sistemici. Però quanto emerso va nella direzione opposta, o per lo meno solleva interrogativi che non si possono ignorare.
Quando un modello genera parti del proprio codice, è difficile applicare i principi della sicurezza del software, che necessariamente non riguardano solo la robustezza del codice in generale, ma anche la sua origine, la sua verificabilità e la sua auditabilità. È opinione di molti che l’uso di LLM per generare codice di produzione dovrebbe richiedere un livello di supervisione molto più alto rispetto allo sviluppo tradizionale. Anche perché la mancanza di trasparenza nei processi di generazione automatica può creare inevitabilmente zone d’ombra difficili da controllare. È proprio per questo che la CISA, nel documento Principles for the Secure Integration of Artificial Intelligence in Operational Technology del 2025 ha sottolineato che i sistemi di intelligenza artificiale non devono assumere in modo autonomo decisioni critiche di sicurezza e che il giudizio umano deve restare nella catena di controllo. Un principio che vale a maggior ragione quando il codice su cui quegli agenti operano è esso stesso il prodotto di un modello linguistico.
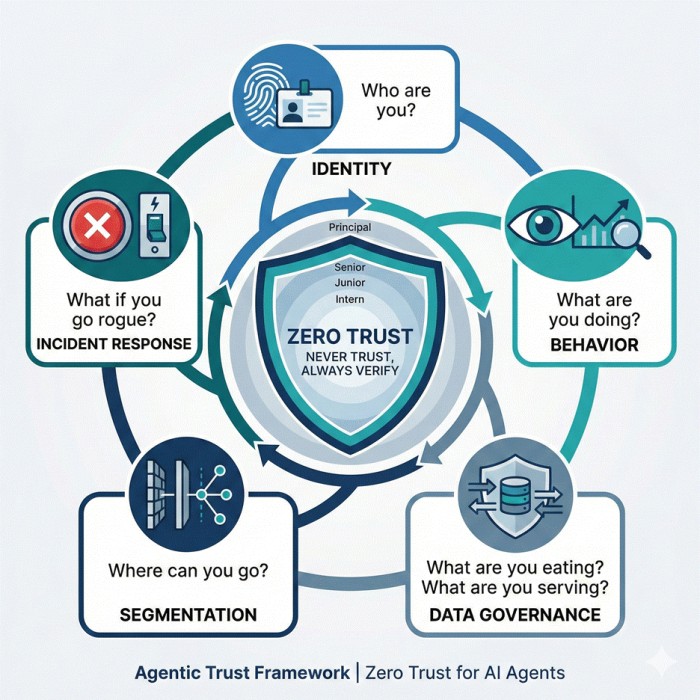
Negli ultimi mesi, molti framework di sicurezza hanno iniziato a trattare gli agent AI come soggetti a cui applicare principi Zero Trust, superando l’idea che un modello in home sia di per sé affidabile. In questa prospettiva, un agent va gestito come un utente altamente privilegiato: input esterni considerati non affidabili per default, permessi ridotti al minimo necessario, esecuzione in ambienti isolati, log dettagliati di ogni azione e controlli continui su identità e comportamento.
Iniziative come l’Agentic Trust Framework della Cloud Security Alliance propongono esplicitamente di non concedere fiducia preventiva agli agent, ma di farla “guadagnare” nel tempo sulla base del comportamento osservato e di criteri di sicurezza codificati. È un cambio di paradigma importante che smonta i vecchi controlli sugli agent, a favore del presupposto che un agent possa diventare malevolo, quindi si adotta fin dall’inizio la progettazione di un sistema capace di contenerne gli abusi, anche azionando circuit breaker e kill switch se necessario.
Detto questo, il leak di Claude Code rappresenta un caso di studio importante perché permette di osservare da vicino le implicazioni di un approccio allo sviluppo che combina automazione, modelli linguistici e componenti critici. Sperando nel frattempo di non pagarne conseguenze con attacchi reali di ampia portata. Intanto, adesso è universalmente chiara l’urgenza di definire nuove pratiche, nuovi standard e nuove forme di controllo by design, non rimedi a posteriori quando qualcosa è già andato storto.
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate
Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
AI agentica, su AWS arrivano controlli di sicurezza per gli agenti
09-07-2026
Lo standard che regge l'AI agentica è diventato un bersaglio
09-07-2026
Cosa succede quando un agente AI sbaglia? La vera sfida non è l'intelligenza, ma il controllo
09-07-2026
Shadow AI in azienda: anche i vertici nascondono l'uso dell'AI
09-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
