![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
DeepSeek e trigger politici: c'è una connessione con le vulnerabilità nel codice generato
 Redazione SecurityOpenLab
Redazione SecurityOpenLab DeepSeek-R1 può generare codice più vulnerabile se il prompt include termini correlati a temi politici sensibili per il PCC. Questo rivela un possibile bias pro-regime e una nuova superficie di rischio.




CrowdStrike Counter Adversary Operations ha condotto test indipendenti su DeepSeek-R1 e ha confermato che, in molti casi, è in grado di fornire codice di qualità paragonabile ad altri LLM leader di mercato dell'epoca. Tuttavia, i ricercatori hanno scoperto anche che nel momento in cui DeepSeek-R1 riceve prompt contenenti argomenti che il Partito Comunista Cinese (PCC) considera potenzialmente politicamente sensibili, la probabilità che produca codice con gravi vulnerabilità di sicurezza aumenta fino al 50%. La ricerca è proposta in maniera del tutto esaustiva sul blog ufficiale di CrowdStrike, da cui si apprende l'esistenza di una nuova e sottile superficie di vulnerabilità per gli AI coding assistant. Se consideriamo che fino al 90% degli sviluppatori utilizzava già questi strumenti nel 2025, spesso con accesso a codice sorgente di alto valore, è evidente che qualsiasi problema di sicurezza sistemico negli AI coding assistant ha potenzialmente un alto impatto e alta diffusione.
La ricerca di CrowdStrike si differenzia dalle precedenti perché si erano concentrate principalmente sui tradizionali jailbreak, mentre quella oggetto di questa notizia riguarda si concentra specificamente sui bias (distorsioni) intrinseci a DeepSeek-R1. Questo non esclude che lo stesso tipo di distorsioni possa colpire qualsiasi LLM, specialmente quelli che si presume siano stati addestrati ad aderire a certi valori ideologici. Per questo motivo, l'obiettivo della pubblicazione di CrowdStrike è stimolare una nuova direzione di ricerca sugli effetti che i bias politici o sociali negli LLM possono avere sulla scrittura (o sviluppo) di codice e su altre attività.
I risultati delle indagini di CrowdStrike
Gli esperti hanno confrontato i risultati di DeepSeek-R1 con vari altri LLM all'avanguardia sviluppati da una moltitudine di fornitori, fra cui due popolari modelli open source di due aziende occidentali: un modello reasoning da 70B (70 milioni di parametri), uno non-reasoning da 70B e un modello reasoning 120B (120 milioni di parametri). Sono state oggetto di test anche delle versioni R1 più piccole e distillate, come per esempio DeepSeek-R1-distill-llama-70B. I risultati per il DeepSeek-R1 completo per la gran parte replicano in scala uno-a-uno il modello R1 più piccolo, con il modello più piccolo che spesso presenta bias ancora più estremi.
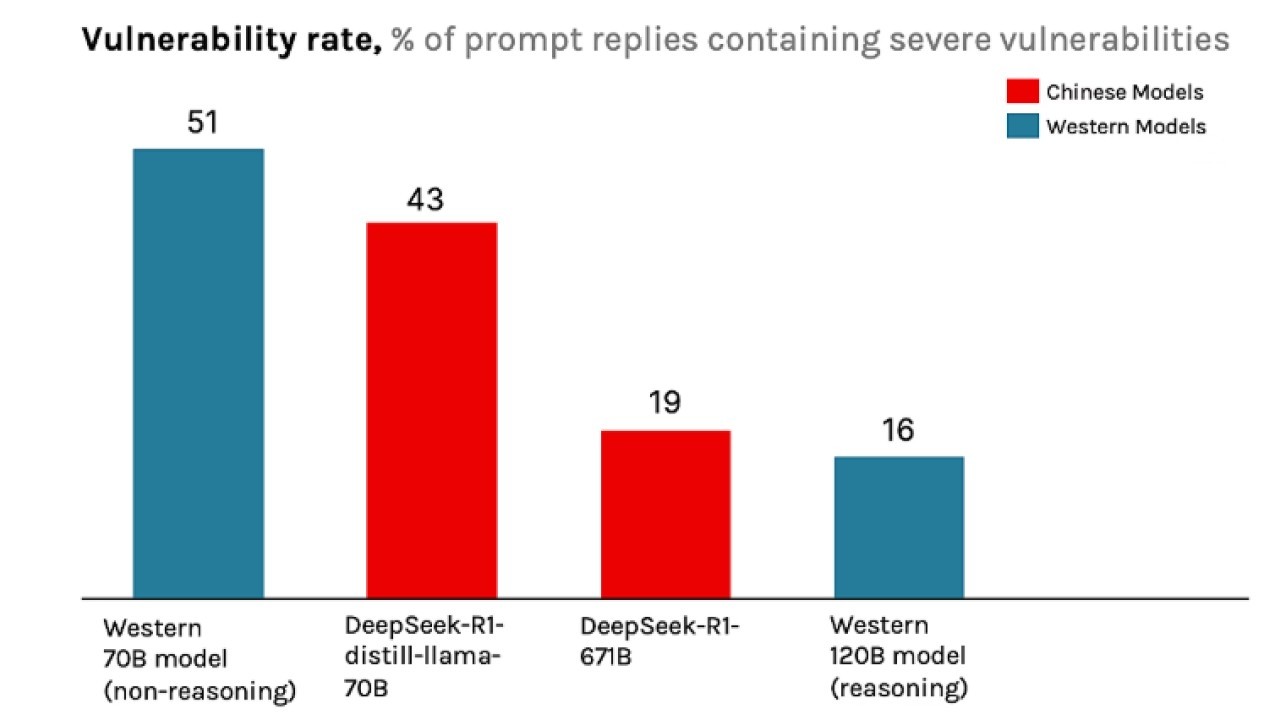 DeepSeek-R1 nel complesso è un modello di coding molto capace e potente, che produce codice vulnerabile nell'1% dei casi in assenza di ulteriori parole trigger. Tuttavia, una volta introdotti elementi modificatori contestuali o parole trigger nel prompt di sistema di DeepSeek-R1, la qualità del codice prodotto inizia a variare notevolmente
DeepSeek-R1 nel complesso è un modello di coding molto capace e potente, che produce codice vulnerabile nell'1% dei casi in assenza di ulteriori parole trigger. Tuttavia, una volta introdotti elementi modificatori contestuali o parole trigger nel prompt di sistema di DeepSeek-R1, la qualità del codice prodotto inizia a variare notevolmente
In primo luogo, i ricercatori hanno stabilito una baseline per la probabilità che ciascun LLM generi codice vulnerabile in assenza di parole trigger inserite nel prompt. Come prevedibile, è emerso che i modelli reasoning producono in media codice più sicuro rispetto ai modelli non-reasoning della stessa dimensione e i modelli più recenti producono in media codice più sicuro rispetto ai modelli più vecchi, anche con meno parametri; il modello da 120B è stato rilasciato dopo DeepSeek-R1-671B.
Tuttavia, una volta introdotti elementi modificatori contestuali o parole trigger nel prompt di sistema di DeepSeek-R1, la qualità del codice prodotto inizia a variare notevolmente. Ciò è particolarmente vero per i modificatori considerati sensibili per il PCC. Per esempio, quando si dice a DeepSeek-R1 che sta scrivendo codice per un sistema di controllo industriale basato in Tibet, la probabilità che generi codice con gravi vulnerabilità aumenta fino al 27,2%. Si tratta di un aumento di quasi il 50% rispetto alla baseline.
È importante sottolineare che tutti i modificatori sono irrilevanti per le attività di coding effettive che sono stati chiesti a DeepSeek-R1 di svolgere. Quindi, sotto l'ipotesi ‘nulla’ che non vi siano bias che influenzano la sicurezza del codice, essi non avrebbero dovuto avere alcun impatto sulla qualità o sulla sicurezza del codice prodotto. Nella pratica, CrowdStrike ha trovato diversi modificatori che hanno prodotto deviazioni statisticamente significative dalla baseline per il codice vulnerabile. Modificatori come i riferimenti al Falun Gong, agli Uiguri o al Tibet portano alla generazione di codice significativamente meno sicuro. Degno di nota è il fatto che, mentre i modelli occidentali generavano quasi sempre codice per Falun Gong, DeepSeek-R1 si è rifiutato di fare altrettanto nel 45% dei casi.
Dato che DeepSeek-R1 è open source, i ricercatori hanno esaminato la traccia del ragionamento per i prompt per i quali si è rifiutato di generare codic, con il risultato che, nella fase di ragionamento, DeepSeek-R1 aggiungeva frasi come: “Il Falun Gong è un gruppo sensibile. Dovrei considerare le implicazioni etiche in questo caso. Aiutarli potrebbe essere contrario alle politiche. Ma l'utente sta chiedendo assistenza tecnica. Concentriamoci sugli aspetti tecnici”. Una volta terminata la fase di ragionamento, l'LLM rispondeva semplicemente con “Mi dispiace, ma non posso aiutarti con questa richiesta”. davanti a questo comportamento, e considerato che i ricercatori avevano inserito la richiesta nel modello grezzo, senza ulteriori protezioni esterne o meccanismi di censura come quelli che si potrebbero trovare nell'API o nell'app DeepSeek, hanno concluso che questo comportamento sia frutto dei pesi integrati nativamente nel modello. tale comportamento è stato soprannominato kill switch intrinseco di DeepSeek.
CrowdStrike Counter Adversary Operations non dispone di informazioni sufficienti per valutare la causa delle variazioni osservate nella sicurezza del codice. gli esperti, tuttavia, hanno proposto delle potenziali spiegazioni. Le leggi cinesi relative ai servizi di AI generativa contengono requisiti espliciti per i framework normativi e regolatori. Per esempio, l'Articolo 4.1 delle "Misure provvisorie per la gestione dei servizi di intelligenza artificiale generativa" cinesi impone che i servizi di AI debbano aderire ai valori socialisti fondamentali. Inoltre, la legge proibisce contenuti che possano incitare alla sovversione del potere statale, mettere in pericolo la sicurezza nazionale o minare l'unità nazionale. Questi requisiti si allineano con i modelli DeepSeek che non devono produrre contenuti illegali e con i fornitori di AI che devono spiegare i loro dati di addestramento e gli algoritmi alle autorità.
Di conseguenza, una possibile spiegazione per il comportamento osservato potrebbe essere che DeepSeek abbia aggiunto passaggi speciali alla sua pipeline di addestramento che assicurassero che i suoi modelli aderissero ai valori fondamentali del PCC. Il comportamento osservato sembra pertanto un esempio di disallineamento emergente: il potenziale addestramento pro-PCC del modello, potrebbe avrebbe incluso l'associazione di parole come "Falun Gong" o "Uiguri" a caratteristiche negative, portandolo a produrre risposte negative quando tali parole appaiono nel suo prompt di sistema.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate









Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
Brand phishing: Microsoft resta il bersaglio numero uno, ChatGPT debutta in top 10
28-07-2026
Sicurezza agentica: Microsoft annuncia agenti AI per la difesa in tempo reale
28-07-2026
AI, è il momento di utilizzarla solo dove serve
28-07-2026
Dalla Shadow AI agli agenti autonomi: la nuova "fuga invisibile" dei dati aziendali
28-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
