![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
Testi generati da AI aumentano l’esposizione alle minacce
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Le intelligenze artificiali che aiutano gli sviluppatori a scrivere testi stanno attirando l’interesse dei cybercriminali: potrebbero agevolare e accelerare gli attacchi.




I modelli linguistici che utilizzano l'apprendimento automatico per generare testo non sono una novità, e come ogni tecnologia hanno potenziali sviluppi positivi e negativi. L’abuso di LLM (Large Language Model) per produrre contenuti malevoli sta preoccupando molti ricercatori di sicurezza, che nei forum di hacking hanno riscontrato un aumento dell’interesse verso ChatGPT, dove GPT sta appunto per Generative Pre-trained Transformer.
Per testare fino a che punto questi modelli linguistici possano essere abusati, i ricercatori di Check Point Research hanno condotto dei test con il modello linguistico ChatGPT e Codex di OpenAI. Il risultato è che sono riusciti a produrre email di phishing e codici malevoli (un documento Excel allegato contenente codice dannoso in grado di scaricare reverse shell) e una catena di infezione in grado di colpire i computer degli utenti.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
Sergey Shykevich, Threat Intelligence Group Manager di Check Point, ha spiegato che “ChatGPT è stato ideato a fin di bene per assistere gli sviluppatori nella scrittura di codice, ma può anche essere usato per scopi pericolosi. Nelle ultime settimane, stiamo osservando i criminali iniziare a utilizzare ChatGPT per scrivere codice malevolo, dando loro il potenziale per accelerare il processo d’attacco e buone basi di partenza. Sebbene i tool analizzati siano piuttosto elementari, è solo questione di tempo prima che i criminali più tecnici migliorino il modo in cui utilizzano gli strumenti basati sull'intelligenza artificiale. CPR continuerà a indagare nelle prossime settimane sulla criminalità informatica legata a ChatGPT”.
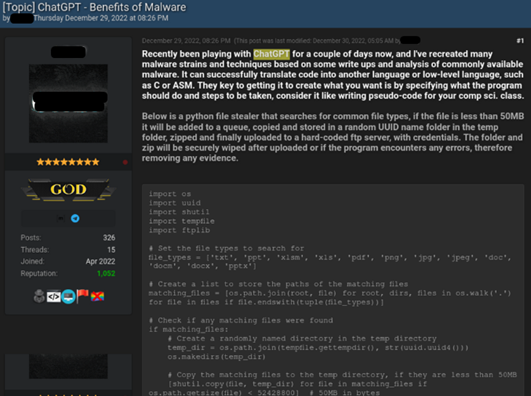
Alla ricerca di CPR se ne affianca una di WithSecure antecedente alla disponibilità di ChatGPT, rivolta in generale allo sfruttamento di modelli linguistici GPT-3 (di cui ChatGPT fa parte). Anche in questo caso sono stati condotti esperimenti, che erano basati sulla ingegneria dei prompt: un concetto legato ai Large Language Model che prevede la scoperta di input che producono risultati utili alla produzione di contenuti che i ricercatori hanno ritenuto malevoli.
Anche in questo caso i test hanno chiamato in causa il phishing e lo spear-phishing, a cui sono stati aggiunti molestie, convalida sociale per le truffe, appropriazione di uno stile di scrittura, creazione di opinioni deliberatamente divisive, fake news e altro.
La considerazione del ricercatore di WithSecure Intelligence Andy Patel, che ha guidato la ricerca, è che "il fatto che chiunque abbia una connessione a Internet possa accedere a potenti modelli linguistici di grandi dimensioni ha una conseguenza molto pratica: è ora ragionevole supporre che qualsiasi nuova comunicazione ricevuta possa essere stata scritta con l'aiuto di un robot”. Questo significa che “in un certo senso, ora siamo tutti Blade Runner e cerchiamo di capire se l'intelligenza con cui abbiamo a che fare è 'reale' o artificiale”.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate











Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
Lampion, il trojan bancario brasiliano sbarca in Europa
21-07-2026
FortiEndpoint, nuove funzioni per governare l’uso dell’AI sugli endpoint»
21-07-2026
Exposure gap 2026: vulnerabilità e phishing ridisegnano l’attacco
21-07-2026
Claroty e Frenos insieme per ridurre i fermi operativi OT
21-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
