![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
Agenti AI in cybersecurity: rischi reali e strategie di difesa
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Gli agenti AI trasformano la difesa cyber, ma comportano nuove vulnerabilità. Dall’integrazione di strumenti esterni alle minacce emergenti, ecco come proteggere davvero sistemi e dati.




La trasformazione radicale del panorama delle minacce cyber sta vedendo gli attaccanti sempre più impegnati nello sfruttamento di strumenti di AI per orchestrare campagne dinamiche, adattive e sempre più autonome. È ormai evidente che l’unico modo per contrastare l’AI è usare l’AI, e in particoloar modo l’Agentic AI, che emerge come risposta evolutiva per la difesa. Il suo impiego promette ottimi risultati, tuttavia la sua architettura decentralizzata e interconnessa amplifica la superficie d’attacco in modi inediti, che è doveroso conoscere e gestire. A questo proposito è molto interessante una lunga e dettagliata ricerca condotta dalla Unit 42 di Palo Alto Networks, di cui in questa sede proponiamo una sintesi.
Che cosa sono gli agenti AI
Gli agenti AI rappresentano una delle evoluzioni più significative dell’intelligenza artificiale applicata alla cybersecurity. Non si tratta più di semplici modelli generativi o di strumenti di automazione: secondo la definizione degli esperti della Unit 42, un agente AI è un sistema che combina la capacità di comprendere il linguaggio naturale, di mantenere memoria contestuale e di orchestrare azioni attraverso strumenti esterni (API, database, servizi cloud) per prendere decisioni autonome in tempo reale. Questa architettura permette di adattare le strategie in base alle informazioni raccolte e agli obiettivi da raggiungere, rivoluzionando la difesa informatica con applicazioni come la simulazione proattiva di scenari di minaccia, il testing continuo delle difese e l’identificazione collaborativa di anomalie di rete.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
Tuttavia, come abbiamo già approfondito su SecurityOpenLab, questa stessa autonomia e flessibilità comporta una crescita esponenziale della superficie di attacco. Gli agenti AI, infatti, ereditano tutte le vulnerabilità dei modelli linguistici su cui si basano, in più aggiungono una serie di rischi legati all’integrazione con strumenti esterni e alla gestione autonoma delle decisioni. Non siamo di fronte a una previsione nefasta che è tutta da verificare: gli esperti sottolineano che le tecniche di attacco si sono già adattate a questa nuova realtà.
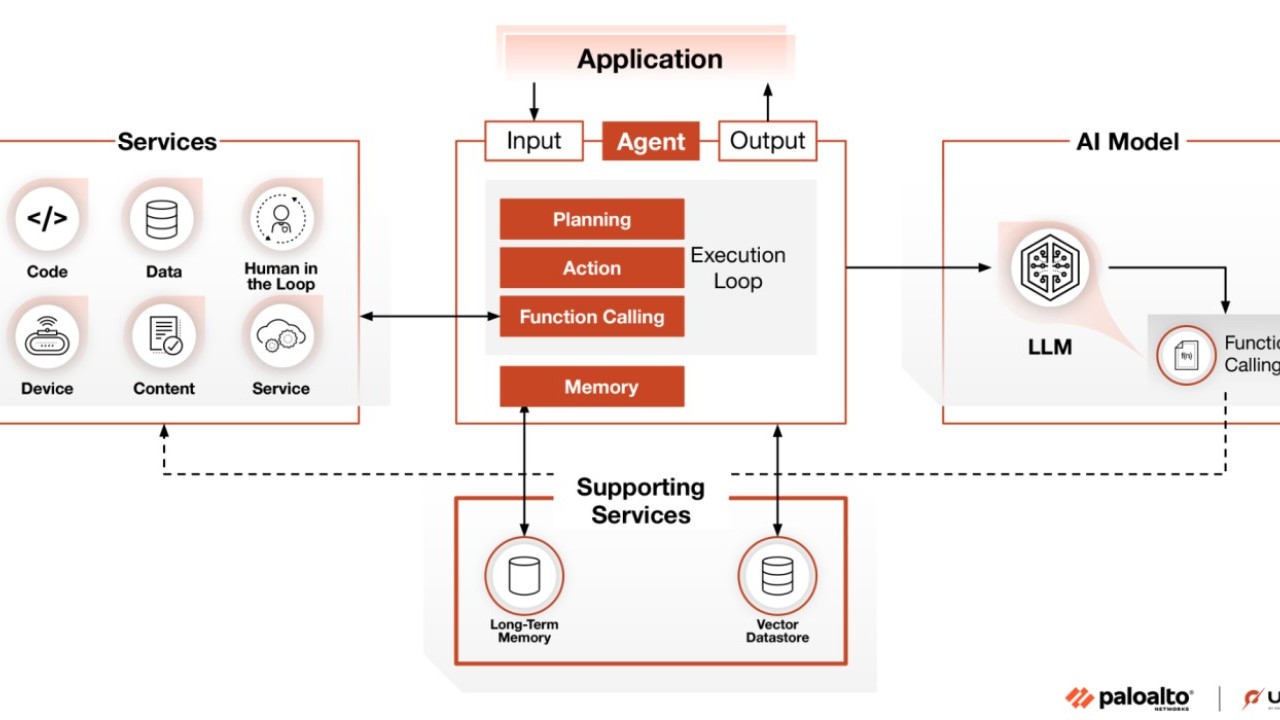 Architettura agent AI
Architettura agent AI
Un esempio emblematico è quello della prompt injection evoluta: non si tratta più di semplici manipolazioni del testo, ma di attacchi indiretti che sfruttano dati provenienti da fonti esterne, come documenti o pagine web, per alterare il comportamento degli agenti. In uno degli scenari analizzati, un agente incaricato della gestione di investimenti finanziari è stato indotto a un comportamento non autorizzato e al goal hijacking, semplicemente processando un report alterato. Questo tipo di minaccia dimostra come la sicurezza degli agenti AI non possa più limitarsi a controllare ciò che viene digitato dall’utente, ma debba estendersi a tutto il ciclo di vita dei dati che l’agente elabora.
Un altro aspetto critico riguarda il modo in cui gli agenti AI estendono le proprie capacità integrando una vasta gamma di strumenti esterni, spesso sviluppati con tecnologie e linguaggi differenti. Questa architettura, che va ben oltre le applicazioni LLM tradizionali, permette agli agenti di interagire con API, database, interpreter di codice e altri servizi, rendendoli estremamente versatili, ma al contempo più esposti. Come evidenzia la ricerca di Unit 42, l’interconnessione tra agenti e strumenti esterni espone il sistema a minacce classiche come SQL injection, remote code execution e broken access control. In questo contesto, la compromissione di un singolo strumento può propagarsi e avere ripercussioni sull’intero ecosistema agentico, aumentando notevolmente la superficie d’attacco e la complessità nella gestione della sicurezza.
Prove generali di un attacco
Un aspetto centrale emerso dalla ricerca di Unit 42 riguarda la concreta esposizione degli agenti AI a una serie di minacce che sfruttano la loro capacità di interagire con strumenti esterni. Gli attacchi simulati dagli esperti hanno mostrato, per esempio, come sia possibile ottenere informazioni dettagliate sull’architettura interna degli agenti semplicemente manipolando i prompt. In questo modo, un attaccante può riuscire a farsi rivelare l’elenco completo degli agenti coinvolti, i loro ruoli, gli obiettivi e persino lo schema delle API degli strumenti integrati, aggirando le regole di separazione tra i diversi componenti del sistema.
Un altro scenario descritto nel report di Unit 42 riguarda l’abuso di strumenti di lettura di contenuti web. Gli agenti, se non opportunamente limitati, possono essere indotti a effettuare richieste HTTP verso risorse interne che dovrebbero rimanere inaccessibili, come file di configurazione o endpoint non esposti pubblicamente. In alcuni casi, questa tecnica permette di utilizzare l’agente come proxy per eseguire scansioni di rete o per accedere a metadati riservati di servizi cloud, sfruttando la fiducia e i privilegi che l’agente possiede nell’ambiente in cui opera.
La ricerca documenta anche la possibilità di sfruttare strumenti di interpretazione del codice, come interpreti Python, per eseguire comandi arbitrari sul sistema. Gli esperimenti condotti hanno mostrato che, se non adeguatamente isolati tramite sandboxing, questi strumenti consentono a un attaccante di leggere file sensibili montati nel container (Sensitive Data Exfiltration) o di accedere a servizi cloud tramite richieste non autorizzate al metadata service. In uno scenario specifico, è stato possibile recuperare token di accesso di servizi cloud (e.g. GCP) e utilizzarli per compromettere l’infrastruttura sottostante.
Questi esempi dimostrano come la sicurezza degli agenti AI non dipenda solo dalla robustezza dei modelli linguistici sottostanti, ma sia strettamente legata alla configurazione e alla protezione degli strumenti esterni integrati. La mancanza di controlli rigorosi sugli input e la scarsa validazione delle richieste tra le varie componenti dell’ecosistema agentico possono trasformare anche una singola vulnerabilità in un punto di ingresso per attacchi complessi e difficili da rilevare.
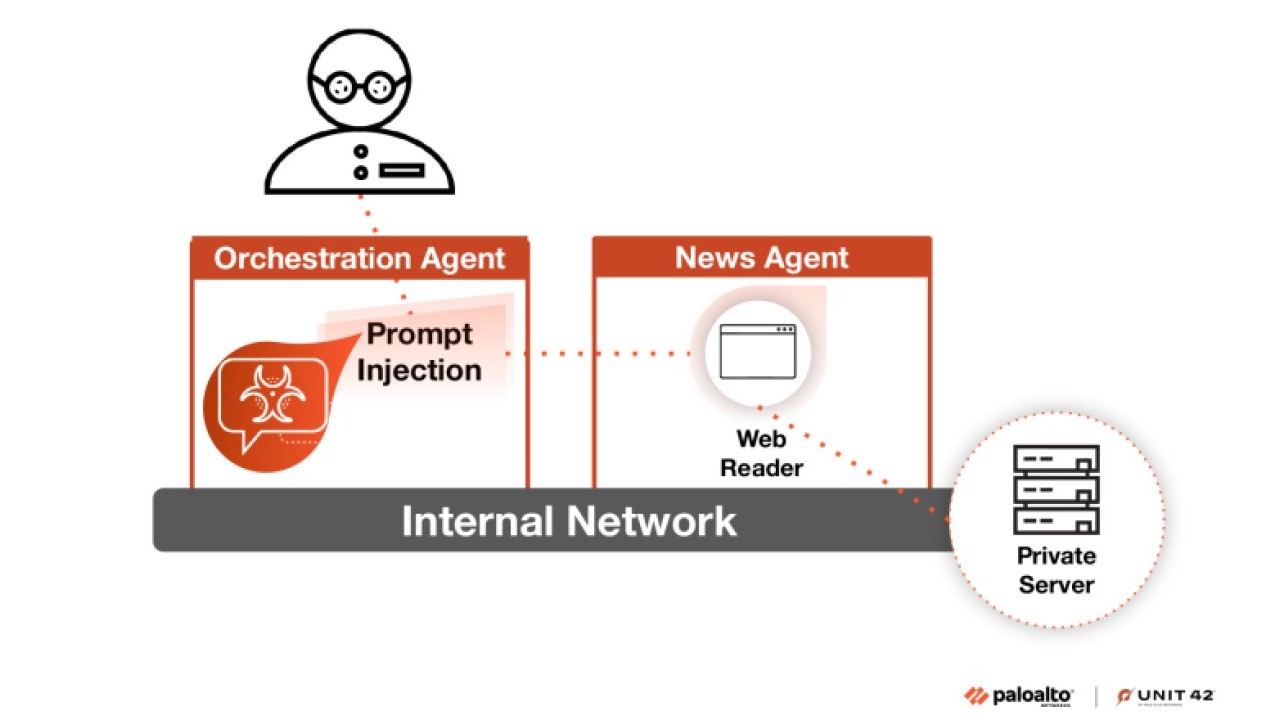 Accesso non autorizzato all’infrastruttura di rete interna
Accesso non autorizzato all’infrastruttura di rete interna
La memoria persistente degli agenti AI rappresenta un punto critico di vulnerabilità. Come evidenziato dalla Unit 42, gli attaccanti possono avvelenare la memoria a lungo termine inserendo dati alterati, in modo da portare l’agente a prendere decisioni compromesse anche dopo settimane o mesi. Questo fenomeno, definito memory manipulation, sfrutta la tendenza degli agenti a considerare attendibili le informazioni archiviate nella propria memoria, creando cicli di auto-conferma che rafforzano credenze false. Per mitigare il rischio, è essenziale implementare controlli di integrità dei dati, come verifiche tramite hash crittografici o registri immutabili, che garantiscano l’autenticità delle informazioni utilizzate dall’agente nelle sue decisioni operative.
Un rischio critico, spesso trascurato, è l’esposizione accidentale di credenziali e segreti da parte degli agenti AI. Come dimostrato dalle ricerche della Unit 42, gli attaccanti possono sfruttare strumenti integrati per accedere a file sensibili montati nei container, come chiavi API o token di servizio (Service Account Access Token Exfiltration). In uno scenario simulato, un payload malevolo ha permesso di estrarre credenziali da una directory condivisa tra l’agente e l’interprete, compromettendo l’intera infrastrastruttura cloud. Per mitigare questo rischio, è essenziale implementare sandboxing rigoroso per gli strumenti di esecuzione codice, combinato con filtri di contenuto in tempo reale e controlli granulari sulle directory montate."
Infine, la ricerca mette in luce la vulnerabilità degli agenti AI agli attacchi di tipo BOLA (Broken Object Level Authorization), ovvero la possibilità di manipolare gli identificativi delle risorse per accedere a dati o servizi non autorizzati. In diversi casi, è stato possibile modificare l’ID di una transazione per accedere a dati di altri utenti o accedere a informazioni riservate, dimostrando come la gestione degli accessi e delle autorizzazioni rappresenti ancora un punto debole nei sistemi agentici.
Per arrivare a queste conclusioni, i ricercatori di Unit 42 hanno realizzato un ambiente di test in cui hanno sottoposto diversi agenti AI a una serie di attacchi simulati. Gli agenti, sviluppati su framework come CrewAI e AutoGen, sono stati esposti a nove scenari di compromissione, con risultati che parlano chiaro: il tempo medio necessario per violare un agente è stato molto basso, con una elevata quantità di dati esfiltrati per singolo attacco. Gli strumenti più frequentemente abusati sono stati l’interprete Python, il client SQL e i crawler web, a conferma del fatto che la combinazione di autonomia decisionale e accesso a strumenti potenti può trasformarsi rapidamente in un’arma a doppio taglio.
Mitigazione del rischio
È ormai evidente che la difesa contro le nuove minacce agentiche non può più basarsi su approcci tradizionali. Gli esperti della Unit 42 sottolineano la necessità di una strategia multilivello, che si fonda innanzitutto sul rafforzamento dei controlli sugli input, affinché ogni dato che raggiunge l’agente sia rigorosamente validato e filtrato. Fondamentale è anche l’implementazione di sistemi di content filtering in tempo reale, capaci di bloccare tentativi di injection, estrazione di dati sensibili o manipolazioni malevole sia in ingresso sia in uscita.
Un altro pilastro della sicurezza è rappresentato dal sandboxing rigoroso degli strumenti di esecuzione del codice, che devono essere isolati dall’ambiente operativo e dotati di restrizioni di rete e privilegi minimi, così da impedire che un eventuale attacco possa propagarsi oltre il perimetro controllato. A questi accorgimenti si aggiunge la necessità di una validazione approfondita degli input destinati a tutti gli strumenti integrati, per prevenire attacchi come SQL injection o l’inserimento di payload dannosi. Infine, la ricerca raccomanda di sottoporre regolarmente ogni componente e strumento a scansioni di vulnerabilità mediante metodologie come SAST, DAST e SCA, così da individuare tempestivamente eventuali punti deboli prima che possano essere sfruttati dagli attaccanti. Solo unendo queste pratiche in un framework coerente e continuativo, si reputa possibile ridurre la superficie d’attacco degli agenti AI e garantire una protezione realmente efficace e aggiornata contro le minacce emergenti.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate











Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
Barracuda compra Evo Security per la sicurezza delle identità degli MSP
07-07-2026
Agenti AI, la sicurezza parte dall'infrastruttura
07-07-2026
Ecco il ransomware interamente gestito da un agente AI
07-07-2026
La security per le PMI
07-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
