![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
AI distribuita e reti quantum‑safe: nuovo fronte per gli attacchi
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Quando i modelli di AI parlano tra loro su canali cifrati, l’attacco può passare per la manipolazione del contesto. Le aziende devono proteggere questi flussi con controlli mirati di anomaly detection.




Negli ultimi anni il dibattito sulla sicurezza post‑quantum si è concentrato per lo più sulla crittografia: algoritmi candidati, standardizzazione NIST, roadmap di migrazione delle infrastrutture esistenti. Come sottolinea anche Intel in un recente approfondimento, tuttavia, man mano che la crittografia diventa più robusta, gli attaccanti alzano il tiro verso gli strati applicativi e logici dei sistemi, puntando su fault e manipolazioni logiche anziché sul semplice breaking degli algoritmi. Per questo motivo iniziano a emergere problemi più sottili legati al modo in cui i dati vengono scambiati e aggregati in ambienti distribuiti, spesso popolati da modelli di AI che dialogano fra loro.
Una delle questioni più interessanti è la cosiddetta anomalous context injection, ossia l’iniezione di contesto anomalo nei flussi di dati che collegano modelli, tool e servizi in scenari protetti da crittografia post‑quantum. L’idea di fondo è semplice: anche se i canali sono cifrati con algoritmi resistenti ai computer quantistici, un attaccante può provare a manipolare il contenuto delle richieste o delle risposte, inserendo istruzioni o dati che alterano il comportamento del sistema. È una sorta di prompt injection estesa al mondo dei protocolli di orchestrazione come per esempio i Model Context Protocol che stanno iniziando a comparire nelle architetture di AI enterprise con una differenza importante: è che in questo caso il bersaglio è l’intera catena di tool che quel modello può attivare.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
Su questo aspetto si sono concentrati gli esperti di Gopher, che hanno pubblicato una serie di analisi tecniche su anomaly detection distribuita e secure aggregation post‑quantum applicate proprio agli ambienti MCP, con l’obiettivo di rilevare in tempo reale le iniezioni di contesto prima che compromettano i flussi di decisione dei modelli. Nel modello descritto da Gopher, la context injection avviene quando un attaccante riesce a inserire comandi o informazioni artefatte nel contesto che guida le decisioni del modello. Il canale di trasporto può essere cifrato con algoritmi post‑quantum e correttamente autenticato, ma se il payload viene manipolato il sistema, continuerà a comportarsi in modo errato perché la manomissione avviene sul contenuto e non sul canale.
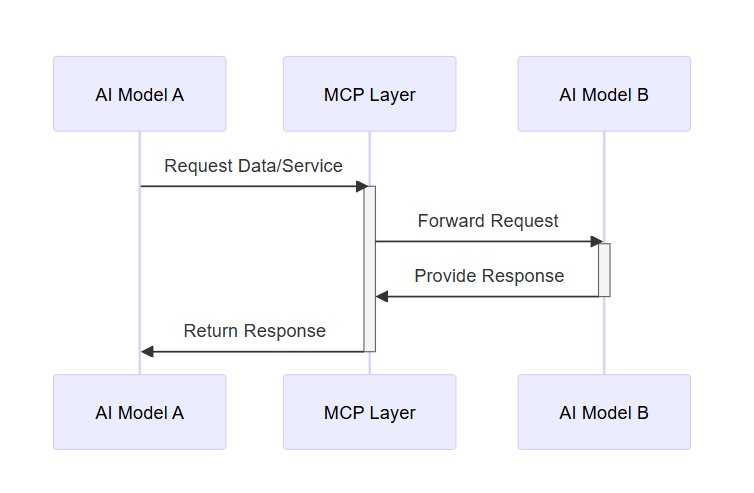 Interazione tra due modelli di AI tramite layer MCP: il primo richiede un dato o un servizio, il layer MCP inoltra la richiesta al secondo modello e restituisce la risposta
Interazione tra due modelli di AI tramite layer MCP: il primo richiede un dato o un servizio, il layer MCP inoltra la richiesta al secondo modello e restituisce la risposta
In un ambiente MCP i modelli scambiano messaggi strutturati che possono contenere parametri di esecuzione, riferimenti a tool esterni, credenziali effimere o richieste di accesso a dati sensibili. Un’iniezione di contesto può spingere il modello a richiamare tool che l’utente non intendeva usare, modificare le policy applicate a un certo flusso di dati aggirando i controlli, oppure introdurre informazioni fuorvianti che portano a decisioni sbagliate in sistemi di detection o automazione. In scenari governativi o finanziari, una deviazione di questo tipo può tradursi, per esempio, nella modifica invisibile di regole di firewalling, di policy di accesso a dataset critici o di parametri operativi di un SOC automatizzato. Il tutto senza che nessuno abbia forzato la cifratura, perché a venire colpito è il contenuto semantico del contesto, non l’involucro crittografico che lo protegge durante il transito.
La dimensione post‑quantum non entra in gioco solo per il classico scenario harvest now, decrypt later di cui si parla tanto. Come sottolinea lo studio di Gopher Security, man mano che le organizzazioni iniziano a usare algoritmi PQC nei propri canali di comunicazione e nei sistemi di federated learning, cambiano anche i modelli di threat detection. In molte architetture moderne i dati, o i relativi indicatori, vengono aggregati da più nodi: sensori distribuiti, agent installati vicino alle sorgenti, microservizi che eseguono inference locale. Per proteggere questi flussi si sperimentano tecniche di secure aggregation compatibili con la crittografia post‑quantum, che combinano primitive come key encapsulation, schemi di secret sharing, crittografia omomorfica e, in alcuni casi, meccanismi di differential privacy.
Un approccio di questo tipo ostacola l’attaccante nell’intercettare o decifrare il traffico, ma non gli impedisce di provare a contaminare il contesto in ingresso o in uscita. Come fanno notare i ricercatori di Gopher, se un nodo compromesso invia dati manipolati, l’aggregatore centrale può faticare a distinguerli, soprattutto quando i dataset originali restano cifrati e non ispezionabili per motivi di privacy o di compliance. Il risultato è un paradosso: si alza il livello di protezione crittografica, ma si rischia di perdere visibilità proprio su quei segnali che servirebbero a riconoscere un’iniezione di contesto.
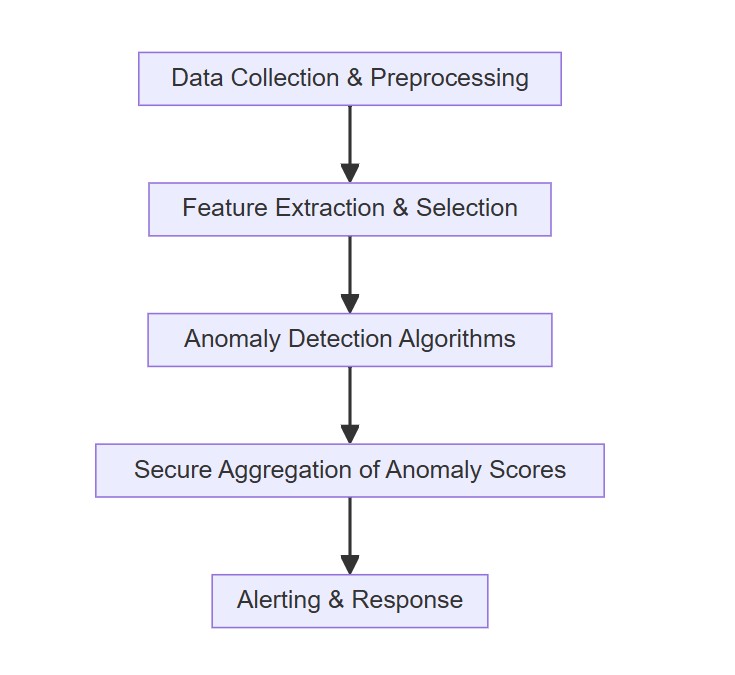 Pipeline di anomaly detection distribuita descritta da Gopher: dai dati grezzi alla secure aggregation degli anomaly score, fino alle fasi di alerting e response
Pipeline di anomaly detection distribuita descritta da Gopher: dai dati grezzi alla secure aggregation degli anomaly score, fino alle fasi di alerting e response
Per mitigare il problema, alcuni lavori citati da Gopher propongono di affiancare una forma di anomaly detection distribuita alla secure aggregation post‑quantum. L’idea è che ogni nodo calcoli localmente un proprio anomaly score sui messaggi che transitano, usando modelli leggeri come autoencoder di ricostruzione, oppure tecniche non supervisionate come isolation forest, o ancora analisi comportamentale delle sequenze MCP. Così facendo ogni nodo invia all’aggregatore centrale solo misure aggregate relative a quanto il contesto osservato si discosti dal comportamento considerato normale.
Gli score così prodotti vengono cifrati con algoritmi post‑quantum e aggregati tramite protocolli di federated anomaly detection. A questo punto l’aggregatore, che lavora sugli score anziché sui dati grezzi, può individuare deviazioni statistiche su larga scala, per esempio un sottoinsieme di nodi che inizia a generare contesti fuori distribuzione o pattern anomali di chiamate a determinati tool, pur senza accedere ai contenuti sensibili. È un modo per far convivere principi Zero Trust, esigenze di privacy e necessità di detection in ambienti dove la cifratura è pervasiva.
Fra i vantaggi evidenti di questo modello ci sono la riduzione della quantità di informazioni sensibili che devono essere decifrate o centralizzate e l’allineamento con le raccomandazioni più recenti sul rischio quantistico e sul design di reti quantum‑safe. Inoltre consente di cogliere pattern di attacco che emergono solo osservando il comportamento collettivo dei nodi. Però ci sono anche limiti pratici: l’adozione di algoritmi post‑quantum introduce un overhead computazionale e di latenza, particolarmente pesante su dispositivi periferici o in ambienti OT. Sono quindi necessarie scelte oculate sulle primitive da usare e sulle frequenze di aggregazione.
C’è anche il tema dell’addestramento: il successo dell’anomaly detection dipende da una fase iniziale in cui il sistema impara che cosa considerare normale. Se l’ambiente è già compromesso quando parte l’apprendimento, esiste il rischio che i pattern malevoli vengano interiorizzati come baseline anziché generare allarmi. A questo si aggiunge un problema di governance: come sottolineato da Gopher, gli alert prodotti da questi meccanismi devono essere integrati in workflow di risposta ben definiti, che includano isolamento automatico dei nodi sospetti, revisione dei permessi MCP, eventuale revoca e rinnovo delle chiavi PQC e, quando serve, roll‑back di modelli o configurazioni contaminati.
Dalla teoria alla pratica
Che cosa significa tutto questo per le aziende che stanno pianificando una transizione verso ambienti quantum‑safe e, allo stesso tempo, stanno introducendo soluzioni di AI distribuite? Il primo passo è la consapevolezza: occorre capire dove, all’interno dell’infrastruttura, stanno nascendo canali di comunicazione tra modelli, tool e servizi (spesso orchestrati via API o protocolli simili a MCP) e quali dati di contesto viaggiano su questi canali. Molti progetti di AI vengono inizialmente trattati come sperimentazioni, poi entrano in produzione e finiscono per connettersi a sistemi di ticketing, console di sicurezza, repository documentali, automazioni infrastrutturali. È su questi punti di contatto che l’iniezione di contesto diventa interessante per un attaccante.
Il secondo passaggio riguarda la strategia post‑quantum: diverse realtà hanno già iniziato a mappare gli asset critici e a pianificare la migrazione a schemi PQC per VPN, canali applicativi e storage. È importante includere nella roadmap i flussi usati dai modelli di AI e dai sistemi di analisi distribuita, per evitare che restino fuori dal perimetro di progetto.
Il terzo livello, infine, riguarda le capacità di detection: chi sta già lavorando con federated learning, orchestrazione di modelli o piattaforme agent‑based può valutare l’introduzione di meccanismi di anomaly detection leggeri vicino alla sorgente dei dati. L’obiettivo è arrivare, nel medio termine, a forme di secure aggregation compatibili con gli standard post‑quantum che NIST e altri organismi stanno consolidando. È banalmente un approccio di security-by-design: iniziare a progettare i nuovi sistemi tenendo anche conto del fatto che molte minacce passeranno dalla manipolazione del contesto.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate











Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
LLM sotto attacco: la vera emergenza non sono le vulnerabilità, ma il tempo che manca ai difensori – l’analisi di Acronis
17-07-2026
AI agentica e cybersecurity: la governance non tiene il passo
17-07-2026
Italia sotto attacco: 2.602 attacchi cyber a settimana a giugno
17-07-2026
Attacco ClickFix nascosto nelle chat condivise di Claude
16-07-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
