![]() : Lascia il tuo voto agli Italian Security Awards 2026
: Lascia il tuo voto agli Italian Security Awards 2026
Un anno di attacchi con l'AI: Anthropic mappa le tecniche su MITRE ATT&CK
 Redazione SecurityOpenLab
Redazione SecurityOpenLab Anthropic ha pubblicato un'analisi che indica come gli attaccanti hanno abusato della sua piattaforma per condurre operazioni offensive.




Anthropic ha pubblicato i risultati di un anno di indagini sul modo in cui gli attaccanti stanno sfruttando i modelli AI per condurre operazioni cyber. Il documento si chiama LLM ATT&CK Navigator e consiste nella prima analisi costruita su dati reali, che mappa Tattiche, Tecniche e Procedure attuate da 832 account bannati per violazione delle policy d'uso di Claude tra marzo 2025 e marzo 2026.
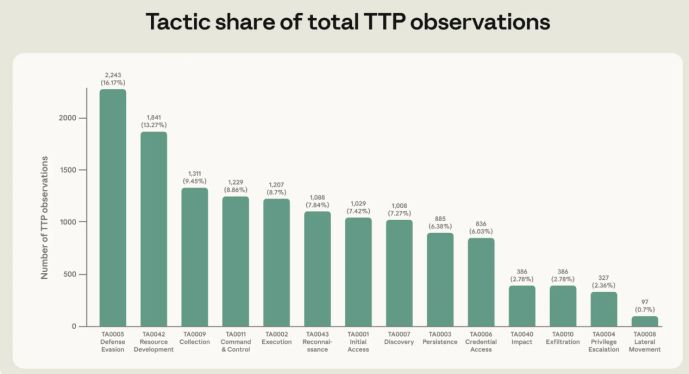
Per ciascuno degli account che Anthropic ha identificato e rimosso per attività malevola legata alla cybersecurity, il team ha estratto le tecniche impiegate e le ha mappate sulla versione più recente del framework MITRE ATT&CK. Il risultato è una raccolta di 13.873 osservazioni, distribuite su 482 sotto-tecniche uniche e su tutte e 14 le tattiche previste dal framework, dalla ricognizione iniziale all'impatto finale.
Partecipa agli ItalianSecurityAwards 2026 ed esprimi il tuo voto premiando le soluzioni di cybersecurity che reputi più innovative
Inoltre, Anthropic ha introdotto una nuova metodologia di scoring chiamata ARiES (AI Risk Enablement Score), che assegna a ogni account un punteggio da 0 a 100 in funzione di tre parametri: il profilo di minaccia del threat actor (intenzione, sofisticazione tecnica, capacità di eludere il rilevamento), la capacità del modello di abilitare il danno richiesto, e l'impatto reale o potenziale dell'operazione.

Che cosa fanno davvero gli attaccanti con l'AI
La tecnica più comune nell'intero dataset è lo sviluppo di capacità offensive, in particolare la scrittura di malware: il 69% degli account analizzati ha usato Claude per costruire o perfezionare strumenti di attacco. Seguono l'offuscamento del codice (64,7%), l'estrazione di dati dai sistemi dell'attaccante stesso (55,9%) e la disabilitazione delle difese (54,9%). La tattica più rappresentata nell'intero campione è l'evasione delle difese, presente per l'84,4% dei threat actor.
La conclusione logica è che l'uso offensivo dell'AI riguarda per lo più la fase pre-intrusione, quando l'attaccante costruisce sui propri sistemi gli strumenti necessari per superare le difese delle potenziali vittime. È un'attività che non è visibile ai difensori, di conseguenza non è rilevabile.
Per ora, le fasi successive alla compromissione iniziale (il movimento laterale all'interno della rete, l’escalation dei privilegi, l'esfiltrazione dei dati) sono minoritarie: solo 54 account su 832 (il 6,5%) hanno usato l'AI per il lateral movement, e meno di 12 vi hanno fatto ricorso per i protocolli di accesso remoto. Ma è una situazione temporanea. Il report analizza anche l'evoluzione nel tempo dell’uso dei modelli AI da parte degli attaccanti, mettendo a confronto i dati della prima metà del periodo di analisi con quelli della seconda. Emerge così che gli attaccanti stanno progressivamente spostando l'uso dell'AI dalle fasi preparatorie verso le operazioni post-compromissione.
Nella seconda metà dell'anno, infatti, il ricorso all'AI per la discovery degli account (l’elenco degli utenti presenti in rete dopo avere ottenuto un accesso iniziale) è cresciuto dell'8,9% e l'esfiltrazione automatizzata è aumentata del 6,2%. Le percentuali sono minime, ma sufficienti per comprendere che l'AI sta iniziando a penetrare anche nelle fasi della kill chain che i team di sicurezza monitorano con maggiore attenzione. Sempre dallo stesso confronto emerge poi che la percentuale di attaccanti nelle categorie maggiori di rischio (medio e alto) è salita dal 33% della prima metà dell'anno al 56% della seconda.
Il report si sofferma anche sul caso GTG-1002 già pubblicato da SecurityOpenLab, caratterizzato dal fatto che gli attaccanti avevano configurato Claude Code su una macchina Kali Linux, collegato strumenti di penetration testing e lasciato che il modello AI ad eseguire da solo tutta la catena di attacco.
MITRE ATT&CK non conosce l'AI agentica
Una delle considerazioni più interessanti del report riguarda un limite di MITRE ATT&CK, che è stato costruito per descrivere quello che un attaccante fa, non come lo fa. L’esempio di GTG-1002 è chiarificatore: tutte le 13.873 azioni osservate nel dataset di Anthropic hanno trovato una corrispondenza nelle categorie esistenti di ATT&CK, ma i comportamenti che rendevano pericoloso GTG-1002 non hanno ancora un ID nel framework. Azioni quali l'orchestrazione autonoma della kill chain da parte di un agente AI, le decisioni in tempo reale basate sull'output dei terminali, l'integrazione di strumenti offensivi nel contesto di un modello tramite MCP, sono capacità nuove, non previste dalla tassonomia con cui i team di sicurezza descrivono le minacce. Ecco perché è urgente aggiornare il vocabolario condiviso della threat intelligence prima che questi attaccanti diventino la norma.
Inoltre, il report di Anthropic mette in discussione l’attuale valutazione del rischio cyber, basata sull’assunto che gli attaccanti più pericolosi siano anche quelli tecnicamente più sofisticati. Nel dataset analizzato da Anthropic, i threat actor a rischio minore hanno usato in media 16 tecniche; quelli a rischio massimo ne hanno usate 20. Morale: quello che distingue un attaccante a rischio critico è come concatena le tecniche e, soprattutto, se riesce a farlo in modo automatizzato.
Tag correlati
Esplora altri articoli su questi argomenti
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato
Notizie correlate










Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
SentinelOne porta l'indagine autonoma nel SOC con Purple AI Agentic Investigation
22-06-2026
Akamai lancia un framework unificato per la sicurezza degli agenti AI
22-06-2026
Un anno di attacchi con l'AI: Anthropic mappa le tecniche su MITRE ATT&CK
22-06-2026
Vecchi router trasformati in proxy per attacchi cyber
22-06-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
